










![[ intranet ]](/images/menu_intranet.png)
![[ festival ]](/images/menu_festival.png)
Acoustic-articulatory inversion
Project Summary
This inversion project aims to estimate the articulatory movements which underpin an acoustic speech signal.
Project Details
What is acoustic-articulatory inversion?
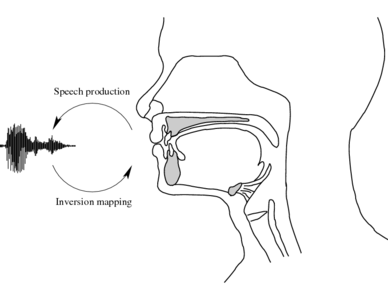 Humans produce an audible speech signal by moving their articulators
(e.g. tongue, lips, velum etc.) to modify and "sculpt" a source of sound
energy in the vocal tract (e.g. air turbulence or vocal fold
vibration).
Humans produce an audible speech signal by moving their articulators
(e.g. tongue, lips, velum etc.) to modify and "sculpt" a source of sound
energy in the vocal tract (e.g. air turbulence or vocal fold
vibration).
In performing the inversion mapping, we aim to invert
this forward direction of speech production. In other words, we aim
to take a speech signal and estimate the underlying articulatory
movements which may have created it.
Why is it interesting/useful?
Speech is transmitted between humans in the acoustic domain, and fortunately, we can easily measure and record that acoustic representation. Underlyingly, however, the acoustic speech signal is the product of events in a speaker's articulatory system, and there has long been interest in ways to exploit the underlying articulatory information for speech technology.
An articulatory representation has certain attractive properties which might be exploited to help in modelling speech. Speech articulators move relatively slowly and smoothly, and their movements are continuous. The mouth cannot jump instantaneously from one configuration to a completely different one. Using speech production knowledge could help improve speech processing methods by providing useful constraints. Suggested applications include, for example, automatic speech recognition, low bit-rate speech coding, speech analysis and synthesis, and animating talking heads.
To use articulatory information in speech processing applications, the articulatory representation itself must somehow be obtained. In recent years, several methods have been developed to measure articulatory movements, such as X-ray microbeam cinematography, Cine-MRI, ultrasound, electropalatography and electromagnetic articulography (EMA). The last two of these in particular are safe enough and cheap enough to enable us to record reasonably large amounts of articulatory data (e.g. the MOCHA TIMIT EMA corpus ). This in turn means the use of machine learning algorithms in common use today in speech technology is viable.
However, although it is now possible to record larger quantities of articulatory data, it unfortunately does not mean it is convenient. All current methods are relatively invasive and require bulky specialist equipment. Therefore, being able to estimate articulation from the acoustic signal alone, aside from being a theoretically interesting problem in itself, would also provide a convenient route to obtaining an articulatory representation of speech for many applications.
Approach taken
The approach taken to the inversion mapping problem in this line of research relies on using corpora of real, measured articulatory data to train machine learning models. In particular, this research project has established the benefit of explicitly addressing the ill-posed nature of the inversion mapping. There is significant evidence to suggest that multiple articulatory configurations can be associated with the same acoustic result. To this end, we have explored models which are capable of modelling one-to-many mappings: the Mixture Density Neural Network (see paper 5 below)
Subsequently, we have extended the mixture density network to provide a full conditional trajectory model, which we have termed the Trajectory Mixture Density Network (see papers 2 and 4 below).
Recently, we have also begun to investigate the sharing of the hidden representation within an inversion mapping model (see paper 3 below), and also Deep Belief Network approaches (publications coming soon!)
Selected project publications
| [1] | K. Richmond. Preliminary inversion mapping results with a new EMA corpus. In Proc. Interspeech, pages 2835-2838, Brighton, UK, September 2009. [ .pdf ] |
| [2] | K. Richmond. Trajectory Mixture Density Networks with multiple mixtures for acoustic-articulatory inversion. In Proc. NOLISP 2007, Paris, France. [ .pdf ] |
| [3] | K. Richmond. A multitask learning perspective on acoustic-articulatory inversion. In Proc. Interspeech, Antwerp, Belgium, August 2007. [ .pdf ] |
| [4] | K. Richmond. A trajectory mixture density network for the acoustic-articulatory inversion mapping. In Proc. Interspeech, Pittsburgh, USA, September 2006. [ .pdf ] |
| [5] | K. Richmond, S. King, and P. Taylor. Modelling the uncertainty in recovering articulation from acoustics. Computer Speech and Language, 17:153-172, 2003. [ .pdf ] |
Prior publications
The following publications predate the current project, but are included here for completeness, since they describe work upon which the present work is founded.
| K. Richmond. Estimating Articulatory Parameters from the Acoustic Speech Signal. PhD thesis, The Centre for Speech Technology Research, Edinburgh University, 2002. [ .ps ] |
| K. Richmond. Mixture density networks, human articulatory data and acoustic-to-articulatory inversion of continuous speech. In Proc. Workshop on Innovation in Speech Processing, pages 259-276. Institute of Acoustics, April 2001. [ .ps ] |
| K. Richmond. Estimating velum height from acoustics during continuous speech. In Proc. Eurospeech, volume 1, pages 149-152, Budapest, Hungary, 1999. [ .ps | .pdf ] |
Duration
January 2002 -
Personnel
- Korin Richmond (Principal Investigator)
Funding Source
(not applicable)