










![[ intranet ]](/images/menu_intranet.png)
![[ festival ]](/images/menu_festival.png)
2012_MMA
The 2012_MMA (multi microphone array) corpus is a corpus of read speech (WSJ) recorded with multiple distant microphone (arrays) enabling research in speaker localisation, (blind) speech separation and speech recognition.Authors
|
Author |
Affiliation |
|
Erich Zwyssig |
The University of Edinburgh |
Data Type
The 2012_MMA corpus contains speech from single and overlapping speakers, following the ideas and setup of the MC-WSJ-AV corpus [1].
Data Source
The MC-WSJ-AV corpus consists of audio recordings generated at premises of the
The Centre for Speech Technology Research
University of Edinburgh
Informatics Forum
10 Crichton Street
Edinburgh
EH8 9AB
United Kingdom
Recordings were carried out using five microphone arrays, as shown in Figure 1
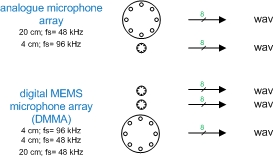
Figure 1 - 2012_MMA corpus recording setup
The configuration for the five circular microphone arrays (diameter d, sampling rate Fs) are:
- Analogue, d = 20 cm, Fs = 48 kHz, 8 channels
- Analogue, d = 4 cm, Fs = 96 kHz, 8 channels
- Digital, d = 20 cm, Fs = 48 kHz, 8 channels
- Digital, d = 4 cm, Fs = 96 kHz, 8 channels
- Digital, d = 4 cm, Fs = 48 kHz, 8 channels
With the analogue microphone (array) containing
- (8 x) Sennheiser MKE 2-P-C microphone
and the digital microphone (arrays) being
- digital MEMS microphone array version 2 (DMMA.2) [2]
- digital MEMS microphone array version 3 (DMMA.3) [3]
built from
Based on the USBPAL from Rigisystems and using eight (8) Analog Devices digital MEMS microphones ADMP441 the DMMA.2 and DMMA.3 are circular microphone arrays with a diameter of 20 and 4 cm. A detailed datasheet and sound samples for the DMMA.3 are available here (DMMA.3).
Recording setup
The recording setup in the IMR and hemi-anechoic chamber are identical within the constraints of the setup.
Figure 2, 3, 4 and 5 show the microphone array placement and adjustment as well as the dimension of the setup with respect to the position of the speaker(s).
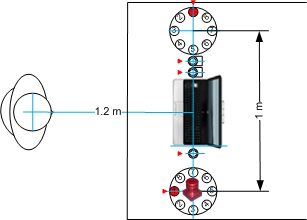
Figure 2 - Recording setup (IMR - one speaker)
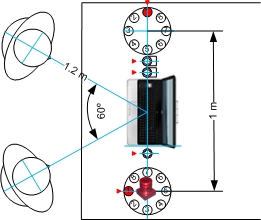
Figure 3 - Recording setup (IMR - two speakers)
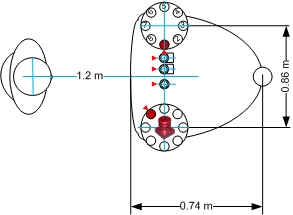
Figure 4 - Recording setup (hemi-anechoic chamber - one speaker)
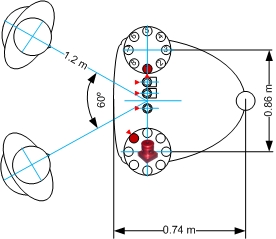
Figure 5 - Recording setup (hemi-anechoic chamber - two speakers)
Note: The red triangle indicates microphone channel 1, channel numbers increase counter-clockwise (in the *.wav audio file provided).
Photos of the setup are shown in Figure 6 and 7.

Figure 6 - Recording setup (IMR)

Figure 7 - Recording setup (hemi-anechoic chamber)
Languages and dialects
UK English.
Narrative Description
The 2012_MMA corpus offers researchers an intermediate task between simple digit recognition and large vocabulary conversational speech recognition. It consists of sentences read from the Wall Street Journal (WSJ) taken from the test set of the WSJCAM0 database.
A total of 24 speakers, 12 male and 12 female, are recorded in two different scenarios, these are:
- single (stationary) speaker
- two (stationary) overlapping speakers
The participants recordings were split equally between an
- instrumented meeting room (6 male/6 female)
- hemi-anechoic chamber (6 male/6 female)
Two same-gender speakers were paired for recording of the overlapping speech.
The speakers are recorded using five different eight-channel microphone array, reading WSJ from prompts. In the single speaker scenario one speaker reads from a fixed position, in the overlapping scenario two speakers read from two fixed positions.
Two times twelve participants were recorded for the single scenario, two times six pairs for the overlapping scenario. Each read about 90 sentences which are available for speech separation and recognition experiments.
|
Task |
Applications |
Comments |
|
Single speaker |
Distant (automatic) speech recognition |
|
|
Overlapping speakers |
Speaker localisation, speech separation and distant (automatic) speech recognition |
|
Each speaker (pair) read WSJ sentences (WSJCAM0) from script, i.e.
|
Data set (name) |
Number of sentences |
Description |
|
adapt |
Approx. 17 |
TIMIT style, for adaptation |
|
5k |
Approx. 40 |
5,000 word (closed vocabulary) sub corpus of WSJCAM0 |
|
20k |
Approx. 40 |
20,000 word (open vocabulary) sub corpus of WSJCAM0 |
Each sentence is individually split from the recording for recognition and stored in folders following the structure
- ./<corpus>/audio/T<#1>[T<#2>]/<mic_type>/{adap|5k\20k}/*.wav
... with
- <corpus> defining the corpus, i.e. WSJ, WSJ_anechoic, MSWSJ or MSWSJ_anechoic
- T<#> defining the participant and his/her number #
- <mic_type> defining the microphone type, i.e. analogue_20cm_48k, analogue_4cm_96k, digital_20cm_48k, digital_4cm_96k, digital_4cm_48k
... and *.wav is defined as
- T<#1><ref#1>_T<#2><ref#2>-<smic_type>.wav
.. with
- <smic_type> defining the microphone type (short form), i.e. a_20_48, a_4_96, d_20_48, d_4_, d _4_48
... and where <ref#> determines the correct answer from the mlf file stored in ./mlf/WSJ.mlf
The speaker locations are stored in ./<corpus>/SentenceLocation/T<>.txt
References
[1] M. Lincoln, I. McCowan, J. Vepa and H.K. Maganti, "The multi-channel Wall Street Journal audio visual corpus (MC-WSJ-AV): Specification and initial experiments", IEEE Workshop on Automatic Speech Recognition and Understanding, 2005
[2] E. Zwyssig, S. Renals and M. Lincoln, "On the effect of SNR and superdirective beamforming in speaker diarisation in meetings", IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2012
[3] E. Zwyssig, F. Faubel, S. Renals and M. Lincoln, "Recognition of overlapping speech using digital MEMS microphone arrays", IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2013